
Three days after Anthropic shipped its best ever model, the US government switched it off for everyone outside America. So I went looking for the next best thing, and OpenRouter reckons it has one.
Anthropic’s best model, behind glass
On 9 June Anthropic released Claude Fable 5 and Mythos 5, the top of its new line. On 12 June the US Commerce Department issued an export control directive citing national security, and Anthropic disabled both models for every foreign national - inside or outside the United States, including its own non-citizen staff. In practice that meant switching them off for all users.
I live in Melbourne. That makes me a foreign national. Anthropic’s best model is, as far as I’m concerned, behind glass.
So the best model I can actually reach is Opus 4.8 - very good, a notch below Fable 5 on the benchmarks. The interesting question becomes how close you can get to frontier results using the tools that remain open.
OpenRouter’s committee of models
That same week, OpenRouter launched Fusion. The pitch: run multiple models side-by-side, analyse their strengths and fuse the best answer. Instead of trusting one model, you send your prompt to a panel. A judge model reads every answer and writes up the consensus, contradictions and blind spots. Then a final model composes the response grounded in that analysis.
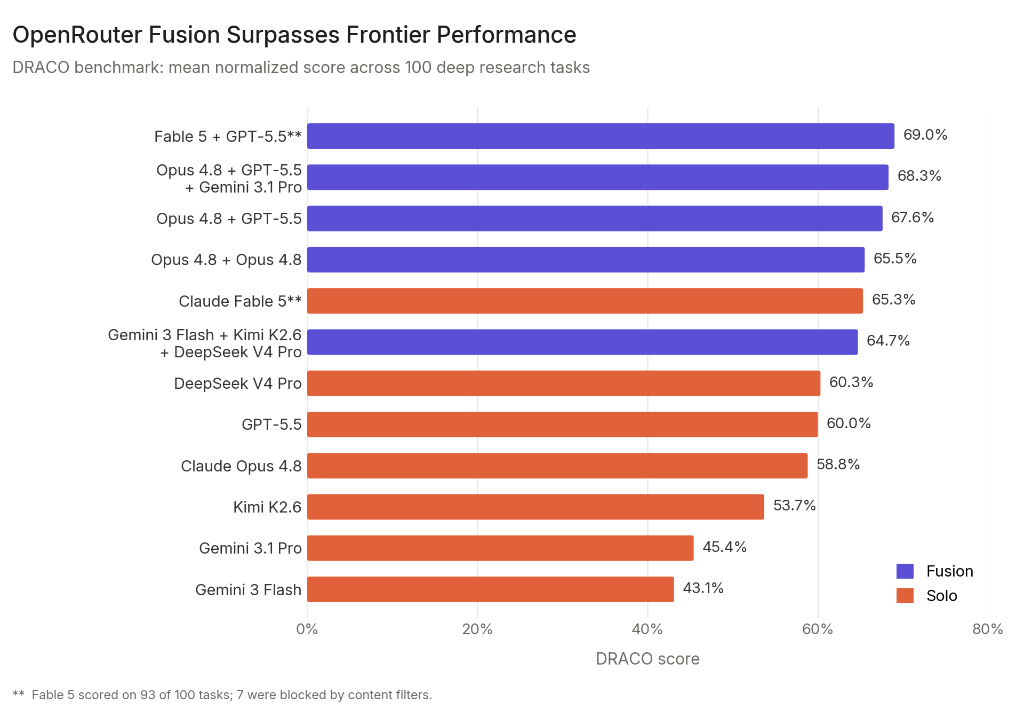
The headline claim is the good bit. On a 100-task deep-research benchmark, a panel of three budget models - Gemini 3 Flash, Kimi K2.6 and DeepSeek V4 Pro, fused by Opus 4.8 - scored 64.7%. Solo Opus 4.8 managed 58.8%. GPT-5.5 got 60.0%. The budget panel landed within a whisker of the banned Fable 5 at 65.3%, for about half the cost.
Cheap models working as a committee, beating the expensive one working alone.
A real problem: six days in the Dolomites
A benchmark is one thing. I had a real problem. I’m planning six days in the Dolomites in September 2027, optimised for scenery and photography, easy walks only. Anyone who has tried to plan this knows the trouble: hundreds of blogs, a shelf of guidebooks, every one of them confident and most of them contradicting each other. For a first-timer it’s a fog.
So I ran the same prompt two ways and paid for it myself, pre-loading OpenRouter credits and using their chat interface. Door one: Opus 4.8 alone. Door two: Fusion, with a budget panel of Gemini 3.5 Flash, DeepSeek V4 Flash and Kimi K2.6, the lot synthesised by Opus 4.8.
What an extra dollar bought
Opus alone: 28.8 US cents, two and a half minutes, one model, one pass. Clean, well structured, genuinely useful.
Fusion: $1.24 US, twelve minutes, 26 separate model calls under the hood. Four times the money, five times the wait.
And worth every cent.
Fusion caught something Opus got wrong. The high cable cars in the Dolomites - Seceda, Alpe di Siusi, Lagazuoi - only run from about 8:30 to 17:30. Which means you cannot be at those summits for sunrise or sunset, the only light a landscape photographer actually wants. Opus didn’t just miss this. It confidently listed Seceda as a sunset spot. For a trip built entirely around light, that’s the kind of error that costs you the photograph you flew around the world for. Fusion flagged it and rerouted golden hour to the road-accessible passes.
It went further. It quantified the climb on every walk, gain in metres, not just distance - exactly what you need when the brief is “easy walks, no hikes”. It added Passo Giau, widely rated the most beautiful pass in the range, which Opus left out entirely. It flagged the drone ban across the national parks and the motorway tolls. And where the panel disagreed on a cable-car fare, it said so and told me to budget high, rather than inventing a tidy number.
Twelve minutes and a dollar and a bit. The whole Fusion run cost less than half a Melbourne flat white. For a once-off plan of a trip I’ll actually take, that premium is a rounding error. The expensive option was, by a distance, the right one.
Where Fusion actually fits
That’s the lesson, and it’s narrower than the marketing. Fusion isn’t a faster horse. It’s slower and dearer than a single model, and for most of what I do - a quick draft, a reformat, a throwaway question - the trade isn’t worth it. Opus or Sonnet alone wins on speed and it wins on cost.
Where Fusion earns its keep is the deep-research job where multiple viewpoints genuinely need weighing and the cost of being wrong is real. Trip planning, oddly, fits. So does anything where you’d otherwise read ten sources and try to reconcile them yourself. The committee does the reconciling, and it catches the thing the confident single voice gets wrong.
The US locked away the best model. It turns out three cheap ones and a referee get you most of the way back - and on the day, further than the best one I’m still allowed to use.
Sources:
- Statement on the US government directive to suspend access to Fable 5 and Mythos 5 - Anthropic
- US orders Anthropic to disable AI models for all foreign nationals - Al Jazeera
- Anthropic disables Fable and Mythos AI models following U.S. government export ban - Fortune
- Model Fusion - OpenRouter
- Surpassing Frontier Performance with Fusion - Brian Thomas, OpenRouter