Same hardware. Same model. Same quality output. Up to four times faster. And you don’t have to spend anything to get it.
That’s DSpark - a new text generation technique just published by DeepSeek. If you run AI models locally, this is going to matter to you.
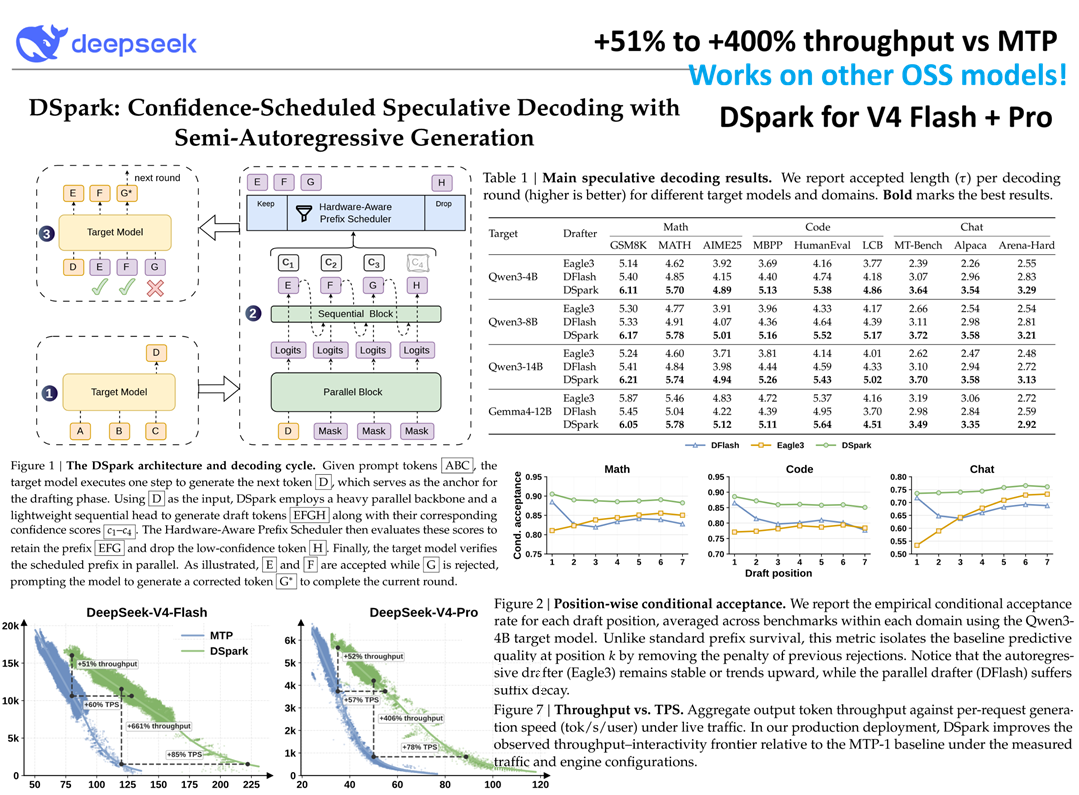
Here’s how it works in plain terms. Current models generate text one word at a time. Each word requires a full pass through the entire model. DSpark changes this by running a lightweight “drafter” alongside the main model. The drafter guesses several words ahead. A scheduler scores those guesses by confidence and only asks the full model to verify the ones it’s unsure about. The high-confidence guesses go straight through.
Think of it like a junior analyst drafting a report and only sending the uncertain paragraphs to the senior partner for review. The senior partner’s workload drops dramatically. The report comes out the same quality, just faster.
DeepSeek tested it on their own V4 models, on Google’s Gemma family and on Alibaba’s Qwen models. The gains held across all of them. The code is open source on Hugging Face. The paper is peer-reviewable. This isn’t a press release with a cherry-picked benchmark. It’s a technique that other teams can verify, adopt and build on.
Why this matters if you run models locally
Most people interact with AI through cloud services. You type into Claude or ChatGPT and some distant server does the work. But a growing number of us run models on our own hardware. A Mac with 48GB or 64GB of unified memory can comfortably run a 12-27 billion parameter model. Not as capable as the frontier cloud models, but fast, private and free after the hardware purchase.
The bottleneck for local models has always been speed. A 27 billion parameter model on a Mac Mini might generate 30-40 tokens per second - roughly the pace of fast reading aloud. Usable, but you notice the wait. Cloud models feel instant by comparison because they’re running on purpose-built GPU clusters.
DSpark closes that gap without any hardware upgrade. If the inference engines that power local model running - llama.cpp, which underpins Ollama, and vLLM for server deployments - integrate DSpark’s technique, every model you’re already running gets faster overnight. You wake up one morning, update Ollama and your existing setup generates text at twice the speed it did yesterday.
No new GPU. No subscription. No cloud costs. Just a software update.
This is the kind of advance that compounds. The models themselves keep improving - Qwen 3.6, Gemma 4, Llama 4 are all more capable at smaller sizes than their predecessors were a year ago. The hardware keeps improving - Apple’s M5 generation pushes memory bandwidth further again. And now the inference layer is improving too, independently of both.
Each of those three layers - model quality, hardware capability, inference efficiency - makes the others more valuable. A better model on faster hardware with smarter inference is multiplicative, not additive. We’re approaching a point where a capable local model running on consumer hardware will be fast enough and smart enough for the majority of daily AI tasks. The cloud becomes the exception, not the rule.
The llama.cpp community moves fast - they’ve historically integrated techniques like this within weeks of publication. Ollama follows shortly after. If you run Ollama today, you’ll get this for free in an update.
And maybe smile at the fact that the most meaningful upgrade to your local AI setup this year won’t require opening your wallet.
Sources:
- DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation - DeepSeek on Hugging Face